Word Embeddings, Cross-Lingual Alignment, and Building CLEU
I spent some time exploring cross-lingual word embeddings — the idea that words in different languages can live in the same vector space and be compared directly. It’s a fascinating corner of NLP that I think deserves more attention. This post covers the concepts and the tool I built to explore them: CLEU.
What Are Word Embeddings
At their core, word embeddings are a way to represent words as numbers. Each word gets mapped to a vector — a list of numbers, typically 200–300 dimensions. The key insight is that words with similar meanings end up with similar vectors.
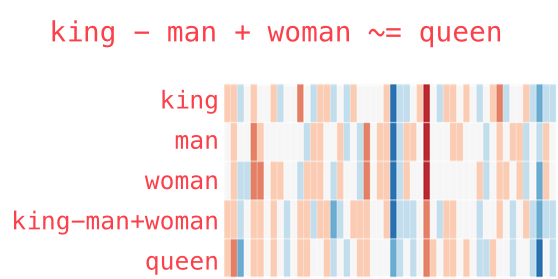
The classic example: if you take the vector for “king”, subtract “man”, and add “woman”, you get something very close to “queen”. The vectors capture semantic relationships — not just that words are similar, but how they relate to each other.
king - man + woman ≈ queen
This works because the training process (Word2Vec, FastText, GloVe) learns from context. Words that appear in similar contexts get similar vectors. “Coffee” and “tea” appear in similar sentences, so their vectors are close. “Coffee” and “democracy” don’t, so they’re far apart.
Cross-Lingual Embeddings
Here’s where it gets interesting. What if we could put words from different languages in the same vector space?
If we align English and Indonesian embeddings, the vector for “cat” in English would be close to the vector for “kucing” in Indonesian. Not because the model knows both languages — but because we’ve mapped their separate vector spaces into a shared one.

There are two main approaches:
Supervised alignment uses a bilingual dictionary — pairs of known translations like (cat, kucing), (house, rumah) — as anchor points. The algorithm learns a rotation matrix that maps one vector space onto the other, aligning the anchor points and generalizing to the rest of the vocabulary. This is called Procrustes alignment.
Unsupervised alignment doesn’t need any dictionary at all. It uses adversarial training to find the mapping — a generator tries to transform embeddings from one language to look like the other, while a discriminator tries to tell them apart. When the discriminator can’t distinguish between the two, the alignment is good. Facebook’s MUSE library implements both approaches.
Why This Matters
Cross-lingual embeddings enable some powerful things:
- Zero-shot translation — find the nearest neighbor of a word in another language’s embedding space
- Cross-lingual search — search for content in one language using a query in another
- Transfer learning — train an NLP model on English data and apply it to Indonesian, even without Indonesian training data
For low-resource languages — languages with limited training data — this is particularly valuable. You can leverage the abundance of English NLP resources for languages that don’t have them.
FAISS — Making Similarity Search Fast
Once you have embeddings, the most common operation is finding nearest neighbors — given a word vector, what are the closest vectors in the space?
Brute-force search works for small vocabularies, but real-world embeddings have hundreds of thousands of words in 300-dimensional space. That’s where FAISS comes in.
FAISS (Facebook AI Similarity Search) is a library optimized for fast similarity search on dense vectors. Instead of comparing your query against every single vector, FAISS builds an index structure that dramatically narrows down the search space.
The basic flow:
- Load your word vectors into a FAISS index
- Give it a query vector
- FAISS returns the k nearest neighbors
FAISS supports different index types depending on your trade-off between speed and accuracy:
- Flat index — exact search, compares against every vector. Accurate but slow for large datasets
- IVF (Inverted File Index) — clusters vectors first, then only searches relevant clusters. Much faster, slightly less accurate
- HNSW (Hierarchical Navigable Small World) — graph-based approach, very fast with high recall
For word embeddings with vocabularies under a million words, a flat index is usually fast enough. For larger-scale applications, IVF or HNSW makes the search near-instantaneous.
The Hubness Problem
One tricky issue with nearest-neighbor search in high-dimensional spaces is the hubness problem. Some vectors become “hubs” — they appear as nearest neighbors to a disproportionate number of other vectors, even when they’re not semantically related.
This is especially problematic for cross-lingual search. A word in one language might always show up as a nearest neighbor simply because of the geometry of the high-dimensional space, not because of actual semantic similarity.
The solution I used in CLEU is CSLS (Cross-domain Similarity Local Scaling). Instead of raw cosine similarity, CSLS adjusts the score by considering how many neighbors each vector already has. Hub vectors get penalized, pushing genuinely similar pairs to the top.
Building CLEU
I built CLEU to make it easier to explore these concepts interactively. It’s a Python library that lets you:
- Load word embeddings for multiple languages
- Search for nearest neighbors across languages using FAISS
- Choose between cosine similarity and CSLS distance
- Visualize embedding spaces with UMAP dimensionality reduction
- Generate similarity matrices and neighbor relationship diagrams
The idea was to have a tool where you could quickly explore questions like:
- What are the nearest Indonesian neighbors of the English word “democracy”?
- How well do the aligned spaces overlap for a specific set of words?
- What does the embedding space look like when you project it down to 2D?
CLEU uses FAISS under the hood for the similarity search, UMAP for dimensionality reduction (which preserves local structure better than t-SNE for this use case), and Altair for interactive visualizations.
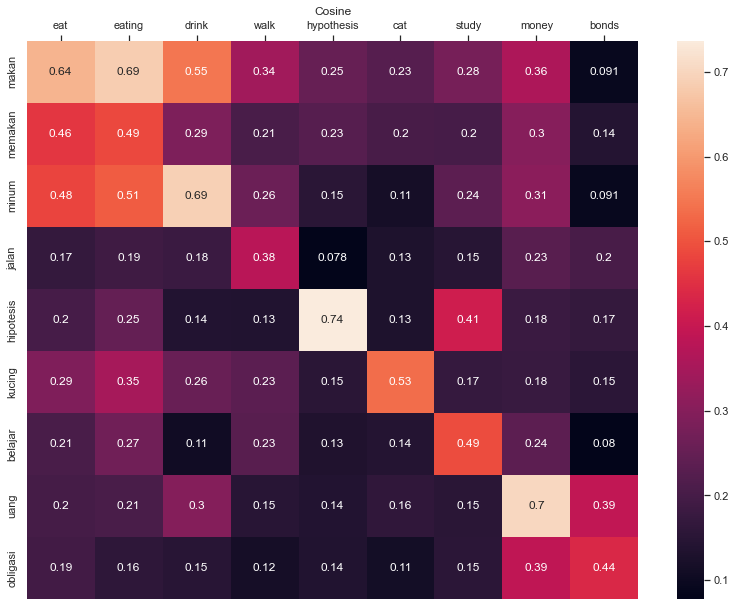
Here’s a similarity matrix generated by CLEU, showing how words across languages relate to each other:
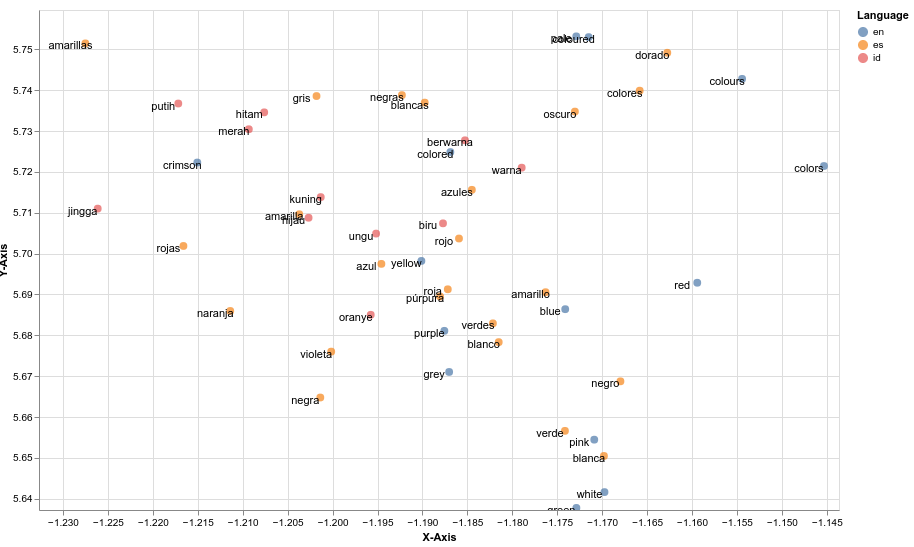
UMAP projection of the embedding space down to 2D — words from different languages that share meaning cluster together:
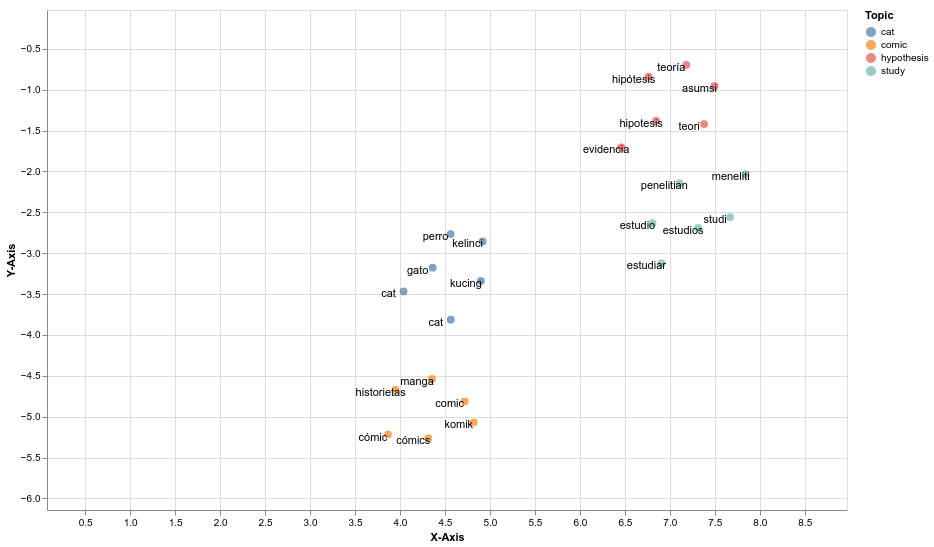
And a neighbor relationship diagram showing cross-lingual nearest neighbors:
Related
Building a Full-Stack App: From Idea to Production
A walkthrough of how I build a full-stack application — from architecture decisions to deployment, using TypeScript, PostgreSQL, and Docker.
Behind bakuhantam.tv — Building a Real-Time Live Streaming Platform
A look behind bakuhantam.tv, a real-time pay-per-view live streaming platform for an Indonesian combat sports event — the streaming pipeline, the coin economy, and the things that nearly broke.
Git Tags, Drone CI, and Watchtower — A Simple Deployment Pipeline
How I moved from Jenkins to Drone CI with git tags and Watchtower for a lightweight, reliable deployment pipeline.